HTML import preprocessing with Javascript
4 min read
last updated: 03/27/2024
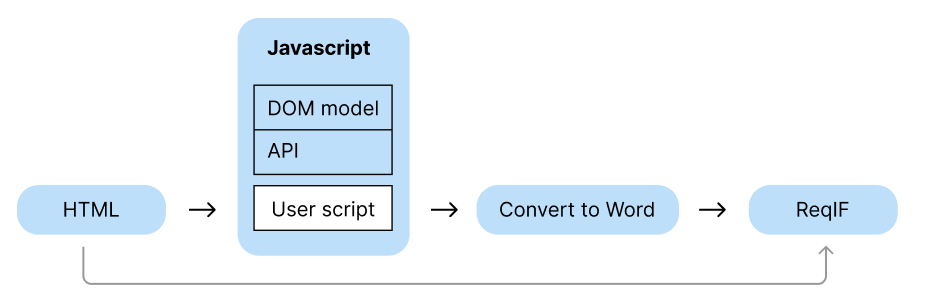
The Javascript engine enables users to do preprocessing on the html content directly before importing to ReqIF. If no userscript is not selected the pre-processing part is skipped.
The javascript engine is https://github.com/paulbartrum/jurassic – a standalone JS engine with no other dependency, therefore only a reduced set of features are available from the browser world.
Javascript API v.1
| function | description |
|---|---|
| removeElementByID(id) | id attribute to match and delete |
| removeElements(nodes) | remove the nodes from the dom object |
| getElementsBy(node, tag, css, id) | get back a list of html objects from the specified node optionally filtered by tag name (cs), css class name (ci) or id attribute (ci) |
| getFirstNodesBy(node, tag) | get back the first child node under the specified node that is the specified tag name |
| trimAll(val) | replace all starting and trailing whitespace characters and all newlines with spaces in val |
| hasClass(node, val) | detect if the specified node contains the specified class name (ci) by val |
| hasID(node, val) | detect if the specified node has the specified ID name (ci) by val |
User javascript
Each user javascript receives the htmlstring containing the html raw content and must return a htmlstring value by calling setReturnValue(htmlstring). A doc object is available that is basic DOM model of the hierarchical nodes of the htmlstring.
doc – the DOM model based on – https://github.com/xmldom/xmldom (v0.8.6)
Large HTML splitting
Javascript runner has a limitation processing large HTML source files, the content has to be splitted. This is done with the following annotations (in the comment, that’s right)
contentSelector and excludeSelector – uses https://github.com/hcesar/HtmlAgilityPack.CssSelector engine
| variable | description |
|---|---|
| contentSelector | split the html file into multiple elements, each element will be processed separately |
| excludeSelector | exclude elements from the list based on the specified selector – currently in development |
Example script
/*
contentSelector = "body > *"
excludeSelector = ".footnote, .notes"
*/
// PERFORM CUSTOM ACTIONS
var tables = getElementsBy(doc, "table", "table"); // tables with .table class
var images = getElementsBy(doc, "img");
//console.log("table" + tables.length + " images" + images.length)
// node can be .table or can contain images - leave alone
// node contains super/sub formatted strings replace tags
if (!tables.length) {
if (!images.length) {
// if structural table
if (doc.firstChild.nodeName.toLowerCase() == "table") {
var line = "<p class='object'>";
// process first row
var trs = getFirstNodesBy(doc, 'tr');
for (var i = 0; i < trs[0].childNodes.length; i++) {
var td = trs[0].childNodes[i];
//console.log(td.nodeName + " " + trimAll(td.textContent));
if (trimAll(td.textContent)) {
// first p of TD
// var firstp = getFirstNodesBy(td, 'p');
// line += trimAll(firstp[0].textContent)+" ";
//console.log(trimAll(td.textContent));
for (var ii = 0; ii < td.childNodes.length; ii++) {
if (td.childNodes[ii].nodeName.toLowerCase() != "table") {
line += trimAll(td.childNodes[ii].textContent) + " ";
}
}
var subtables = getFirstNodesBy(td, 'table');
if (subtables.length) {
line += "<br>";
var l2tables = getFirstNodesBy(td, "table");
l2tables.forEach(function (table) {
line += trimAll(table.textContent) + "<br>";
//console.log(trimAll(table.textContent));
})
}
}
}
line += "</p>";
//console.log("line");
htmlstring = line;
/*
htmlstring = htmlstring.replace(/<span class="super">(.+?)<\/span>/ig, "<sup>$1</sup>");
htmlstring = htmlstring.replace(/<span class="sub">(.+?)<\/span>/ig, "<sub>$1</sub>");
htmlstring = "<p>" + doc.firstChild.textContent + "</p>";
*/
} else
if (doc.firstChild.nodeName.toLowerCase() == "div") {
// annex that has to be processed again
//console.log('div annex');
htmlstring = doc.toString();
}
else
{
var elem = doc.firstChild;
// is not a table
// starts with number
if (/\d+/i.test(elem.textContent)) {
htmlstring = "<p class='object'>" + elem.textContent + "</p>";
//console.log("p ");
} else
if (hasClass(elem, 'ti-art') || hasID(elem)) {
htmlstring = "<h1 class='object heading'>" + elem.textContent + "</h1>";
//console.log("h1 ");
} else
if (hasClass(elem,'.sti-art')) {
htmlstring = "<h2 class='object heading'>" + doc.firstChild.textContent + "</h2>";
//console.log("h2 ");
} else {
htmlstring = "<small>" + doc.firstChild.textContent + "</small>";
//console.log("small ");
}
}
//htmlstring = doc.toString();
} else {
// has images
// do not change
//console.log("has image");
htmlstring = doc.toString();
}
} else {
// content is other then tables
// do not change
//console.log("is table");
htmlstring = doc.toString();
}
//htmlstring = doc.toString();
setReturnValue(htmlstring);Testing
ReqEdit will execute whatever the userscript contains. Any errors are logged back to the user.
One way of testing is to use JSBIN https://jsbin.com/?js,console – online js sandbox, where the userscript can be tested with html parts. The contentSelector and excludeSelector will not work.
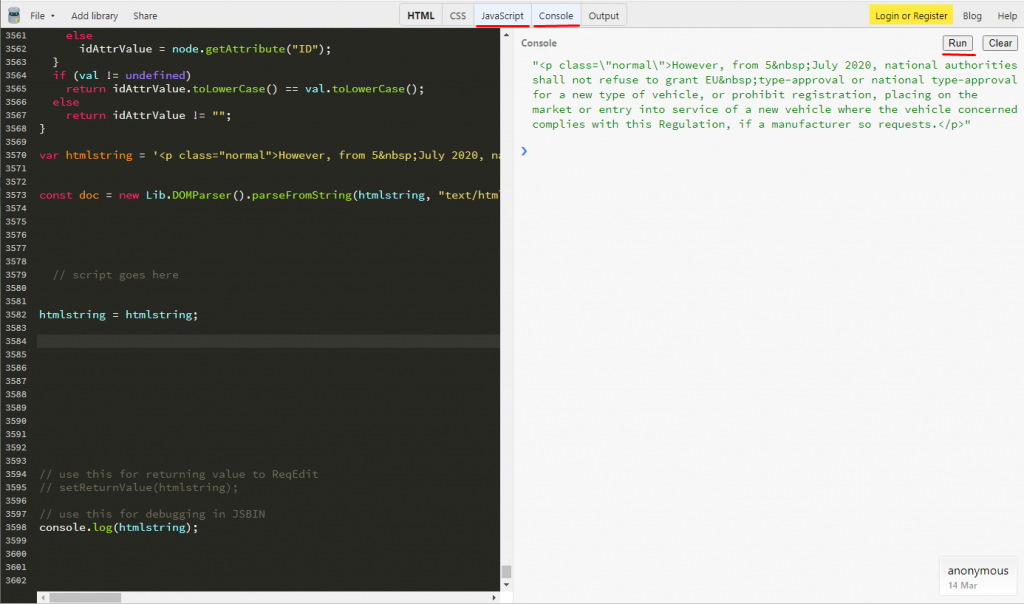
Always use the actual scripts available in ReqEdit.
- Take the ReqEdit/Data/JavascriptEngine/dom-parser.js and
ReqEdit/Data/JavascriptEngine/jsapi.js and paste it in the Javascript panel. - Add the custom script
- End the script with console.log(…) to test the output of the script
- using in ReqEdit setReturnValue(htmlstring) must be used
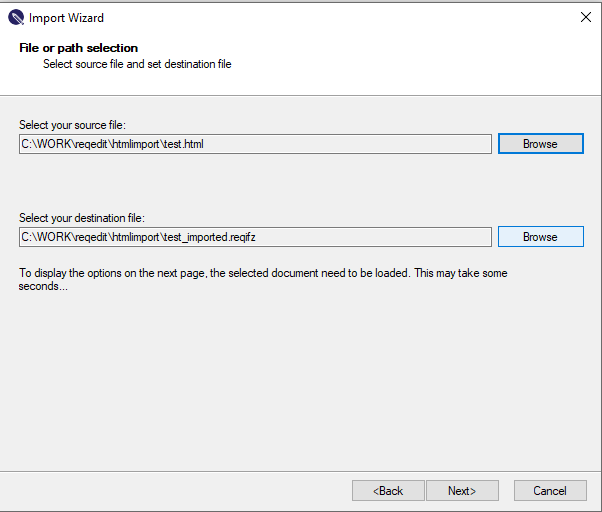
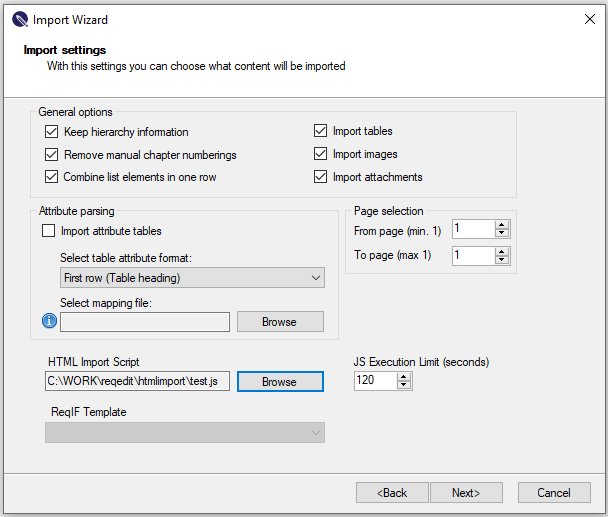
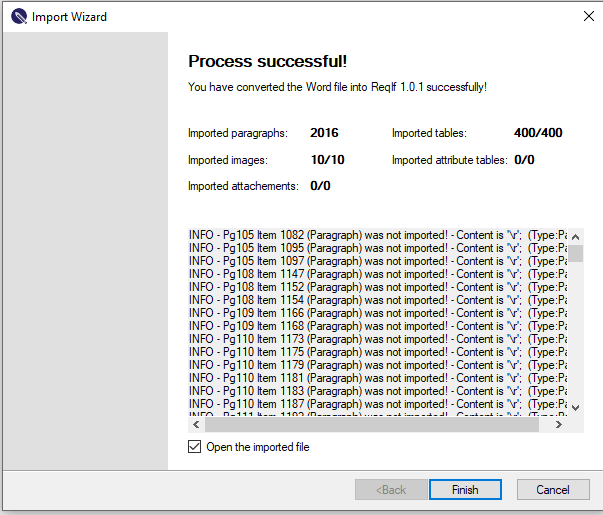
Running in ReqEdit
Tips
Clean up and optimize the original HTML as much as possible.
Remove deeply nested elements to produce a nice list of html nodes and let the contentSelector split the html up.
Split large tables into smaller tables.
Create a user script that will clean-up even more the HTML and handle the sup/sub formatting or convert tags.